
Introduction
The intersection of artificial intelligence and blockchain technology presents a frontier ripe with innovation and challenges. As we stand on the cusp of a new era in decentralized computing, three critical design themes emerge as technical for the successful integration of AI into the Web3.0 ecosystem: composability, interoperability, and verifiability. This article delves into these fundamental principles, exploring how they shape the landscape of on-chain AI development and pave the way for a more robust, accessible, and secure decentralized future.
Design Principle #1: Composability
One of the most important features that has enabled open-source software to accelerate at such a rapid pace is its high degree of composability: the ability to take software modules, plug them into an application and immediately benefit from its utility. On-chain applications are the same, the composability of smart contracts empowers developers to combine existing contracts like building blocks, allowing for the rapid creation and deployment of innovative solutions without the need to reinvent the wheel. Through composability, web3.0 ecosystems flourish, fostering collaboration, experimentation, and the evolution of novel primitives on the blockchain.
We foresee the development of on-chain AI to follow a similar theme, we must build modular and composable infrastructure that allows developers to be able to stitch models together seamlessly to enable a renaissance of AI development on the blockchain. Engineers should be able to easily pick and choose models and piece them together like lego blocks together in smart contracts to build powerful use-cases easily. Especially for developing use-cases like autonomous on-chain trading agents, these are likely not going to be powered by monolithic "super models" and will likely be powered by a combination of highly-specialized models aimed to perform specific tasks instead. We can draw parallels to algorithmic trading in quantitative finance, where researchers piece together individual building blocks like forecasting models, convex optimizers, risk models, and more to create sophisticated trading systems instead of using unreliable and unexplainable monolithic models to do end-to-end trading.
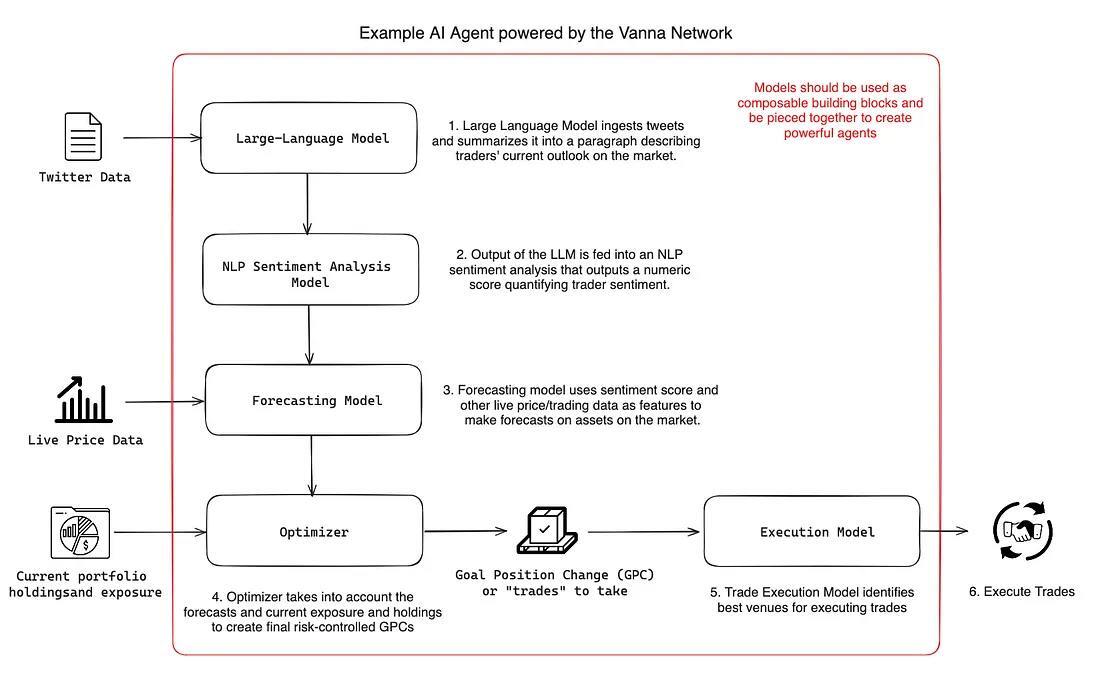
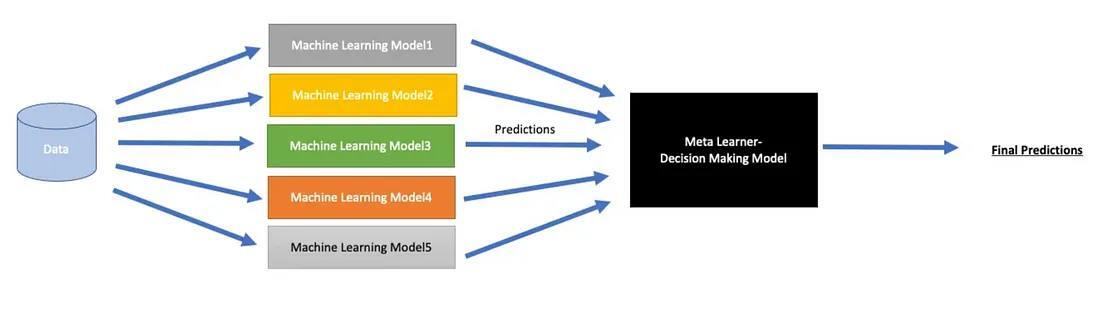
Stacking multiple models together to improve results is hardly a new use-case in the traditional world of machine learning, there is a wealth of existing literature and research on model ensembles and these ideas have existed for a long time. Composability has always been important in the modeling world, as model ensembles are powerful and can lead to more robust results for a couple reasons, the most important being:
- Reducing generalization error — Aggregating model outputs, also known as model stacking, can reduce generalization error of individual models that may have reasons such as overfitting or underfitting to specific datasets.
- Robustness — Model ensembles are typically more robust to noise and variability in the data. If one model makes a mistake due to noise or outliers, other models in the ensemble can compensate for it, leading to more reliable predictions.
- Decorrelation — To make model stacking even more powerful, a meta-model can weight the outputs of models differently (e.g. with a correlation matrix) to appropriately decrease weights for models that have highly-correlated outputs and increase weights for vice versa to maximize the stability of a model's outputs.
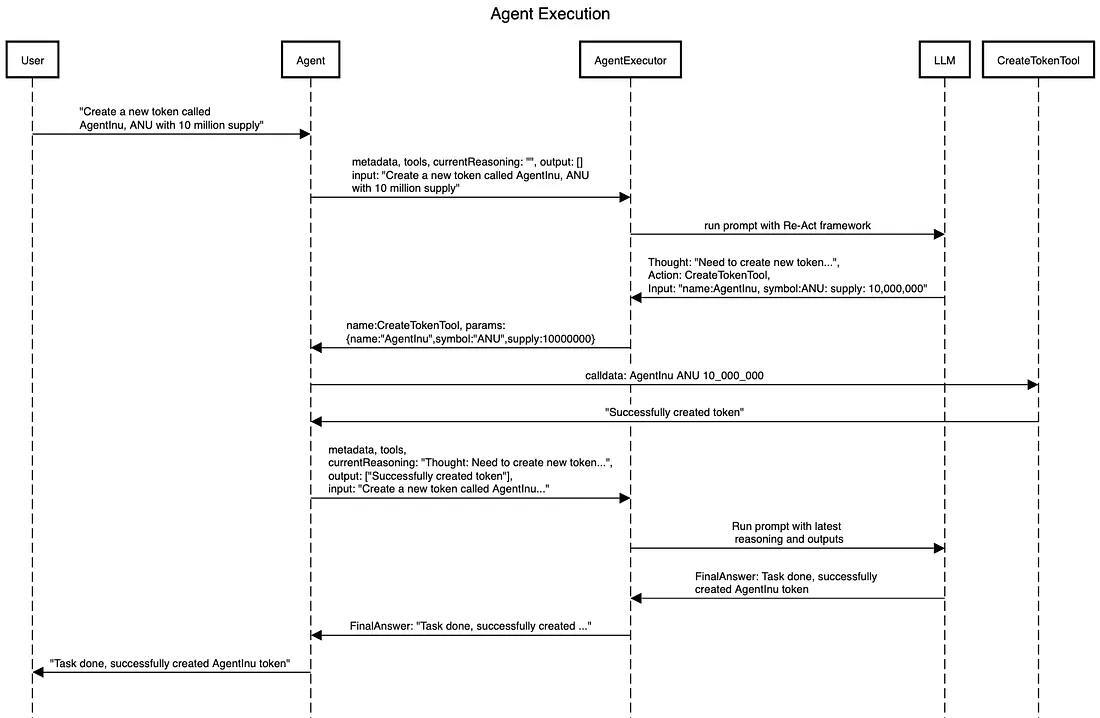
To take full advantage of the composability offered by the blockchain application layer, we've also filed an ERC to propose an extensible framework for designing LLM-backed agents via smart contracts on EVM-based blockchains. The framework will be designed in a way that takes advantage of both the composability and interoperability of smart contracts so agents can communicate and interop seamlessly with each other.
Ultimately, creating an environment with easy access to these hosted models through simple interfaces like a straightforward smart contract function call will allow for maximum composability that would allow for the creation of powerful on-chain use-cases from individual models as building blocks. Your average developer should be abstracted away from mechanisms like model hosting, inference execution, hardware acceleration, and proof generation/validation to be able to rapidly iterate and create new applications.
Design Principle #2: Interoperability
For on-chain AI to thrive, interoperability is crucial. We divide interoperability into two main types: (1) AI models should be universally accessible from anywhere (e.g. smart contracts on other chains, REST APIs...etc) and (2) AI models should have seamless, programmatic access to data, tools, and smart contracts on other chains for maximum effectiveness.
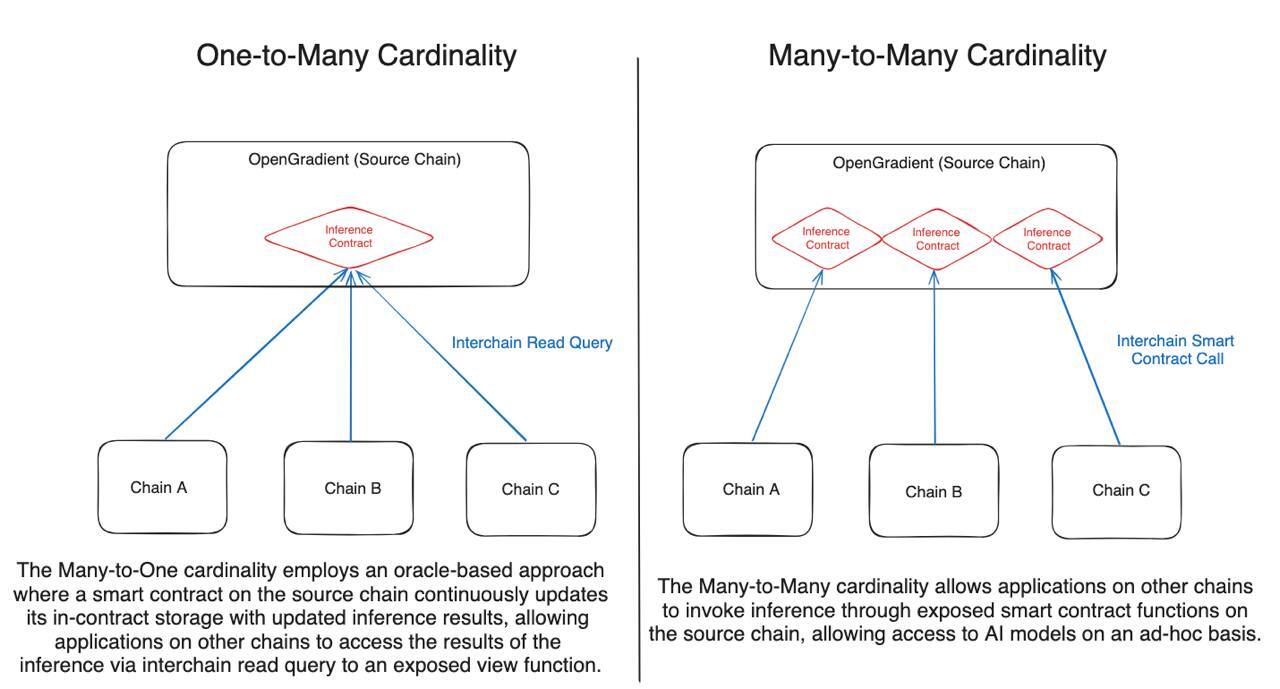
The importance of the former is quite self-explanatory, the model as well as the results of the model should be made available to developers wherever they may be. Primarily, we foresee two types of cardinalities of access to on-chain AI for maximum interoperability: one-to-many which allows the source chain to run on-chain inference and expose the result to multiple chains via a view function that can be accessed via interchain read queries, and many-to-many which allows parties on any chain to invoke cross-chain smart contract calls to run inference on the source chain in an ad-hoc fashion.
As for the latter, models must have access to a wealth of data spanning various chains, decentralized applications, and oracles made available through interoperability protocols for it to reach its full potential. Access to a diverse set of cross-chain data sources empowers AI models to engineer features from disparate sources, enhancing their capabilities and impact. For example, reputation AI models should be able to leverage historical data from multiple chains to improve their classification of whether a certain address is an authentic user or an airdrop-farming bot. Similarly, DeFi risk models should be able to leverage a wide variety of cross-chain data sources for more accurate risk assessments of the market. Interoperability unlocks a vast reservoir of data that facilitates the operation of on-chain AI. The utility of on-chain AI would also be limited if it did not have access to programming interfaces that allowed it to operate seamlessly in a multi-chain fashion. Providing access to a large number of chains and decentralized applications allows these models to perform more actions and simply have more impact.
The above reasons go to show why it's important for on-chain AI to be, well, on-chain. By allowing models to live directly on a chain with built-in features of interoperability, we are able to empower models (or agents) to be accessible from anywhere, while granting them a greater ability to gather data it needs for inference to perform actions on-chain in a variety of modalities that can be tailor-made to different use-cases.
Design Principle #3: Verifiability
Computational verifiability, as a generic concept, is a recurring theme in all peer-to-peer networks. As an example, validators on proof-of-stake networks must attest to the validity of a block for consensus to be reached, which effectively ensures the integrity and verifies the transactions of the proposed block through cryptoeconomic security. This age-old idea is no different for inference of on-chain AI models. Varying degrees of security are needed in order to completely prevent or deter adversarial attack vectors on consumers of inference. This is especially important in the context of AI, where models are often a black box and the explainability of the results are low.
It's important to note that different use-cases will require different levels of verifiability. For high-leverage use-cases in DeFi where an inference result will impact trades it will be vital for the computation to be verified cryptographically, while optimistic security mechanisms like ZK fraud proofs or opML or may be better suited for use-cases like generating dialogue with LLMs for NPCs in on-chain games where immediate security isn't top-of-mind.
It's important for the future of Web3.0 x AI infrastructure to provide a multitude of inference security options that offer a variety of tradeoffs in cost and security to be able to encompass all sorts of on-chain use-cases. Developers should be able to easily pick and choose whatever mode of security they would like to fit their use-case from a latency, cost, and practicality standpoint.
Enter: OpenGradient
OpenGradient is building an EVM-compatible blockchain network that aims to be the scalable and secure execution layer for AI. The network features a revolutionary approach to reinventing blockchain architecture, allowing developers to inference AI models directly from their solidity smart contracts with a simple function call.
Since the OpenGradient Network directly offers access to inference AI models via precompiles in smart contracts, it is able to take maximum advantage of the composability of smart contracts. Simply string inference calls to different models in your smart contract and you'll be able to easily create powerful use-cases.
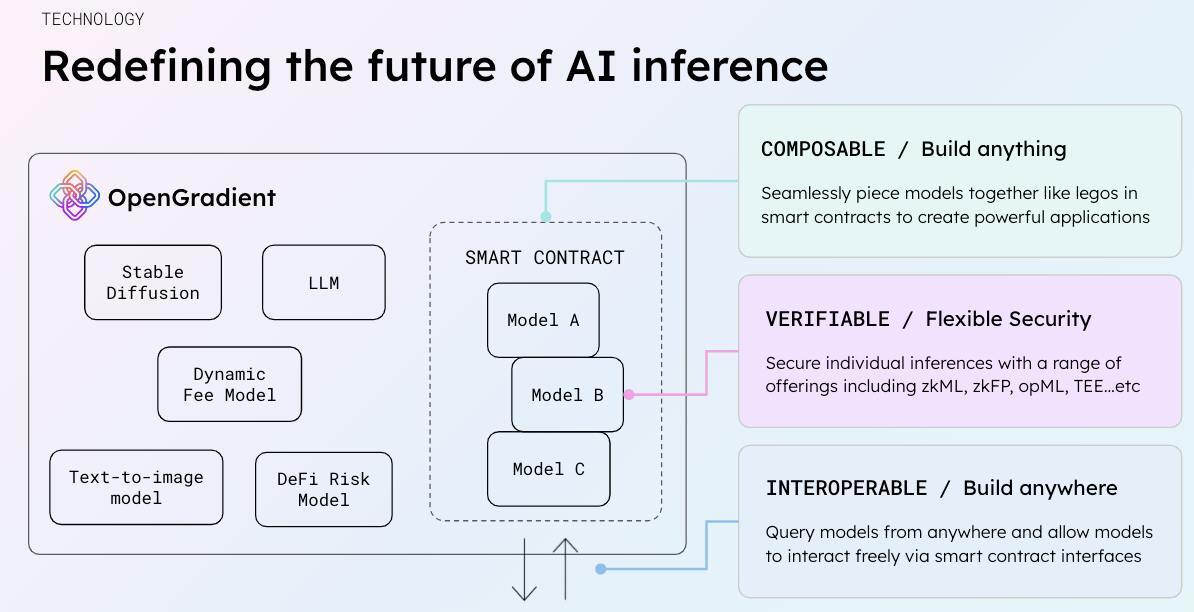
As for interoperability, since OpenGradient is an EVM-compatible network, smart contracts on OpenGradient are able to interact with contracts on other chains via interchain queries and cross-chain calls facilitated by major cross-chain solutions. Having models live on-chain on a network like OpenGradient is powerful, as that allows models to interface with other protocols and models directly; such technical designs maximizes the impact models can have and sets up the Web3.0 world for a renaissance of on-chain AI agents. The OpenGradient team is also cooking up an ERC that architects the future for how on-chain agents and models will interact with each other on EVM-compatible networks.
Lastly, OpenGradient offers a wide selection of a variety of different security mechanisms for inference ranging from cryptographic to cryptoeconomic. The full range of options are listed in our docs here, so regardless of whether you need immediate high-cost cryptographic security or optimistic cryptoeconomic security, we're sure you'll be able to find a solution that fits your use-case. Block data and inference artifacts are all batch-posted and persisted to the data availability layer as well, allowing anyone to verify the proofs themselves.
Conclusion
The successful decentralization of AI inference within the Web3.0 framework hinges on three critical themes: composability, interoperability, and verifiability. Composability, inspired by the success of open-source software, enables developers to seamlessly combine modular AI components to create innovative applications easily. Interoperability ensures that AI models are universally accessible and can leverage diverse data sources across multiple chains, enhancing their capabilities. Verifiability, essential for maintaining trust and security, is essential to all blockchain compute and offering a variety of choices for developers to choose from to tailor to specific use-cases is vital. We hope this article gave you a good run-down of the technological themes we believe are critical to the success of Web3.0 x AI. Follow our journey here!
Twitter: https://twitter.com/OpenGradient


